

Award-Winning eCommerce SEO
eCommerce SEO is our specialty and we’ve got the awards to prove it. No matter what eCommerce platform you’re on, we’ve worked with it and we’ve ranked it. All of our clients enjoy:
- Services Without Contracts
- Dedicated SEO Managers
- SEO Work Done In The USA
- Award-Winning Results
Proven Results - Client Case Study
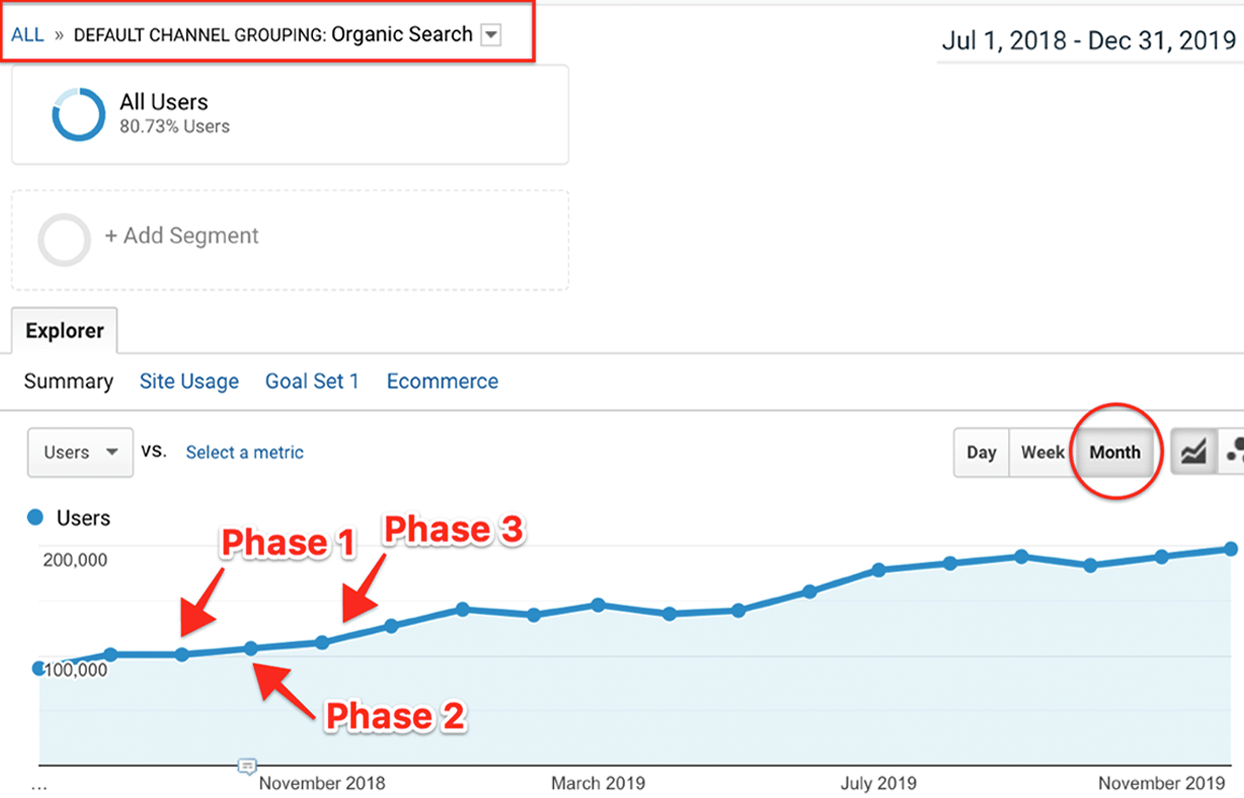
| eCommerce Platform: | Magento |
| Industry/Space: | Jewelry |
This client is on our Fully Managed eCommerce SEO plan which consists of three unique phases of SEO work.
- Deep technical SEO audit (Phase 1)
- SEO strategy developed and approved (Phase 2)
- Execution of SEO strategy (Phase 3, ongoing)
- Results – doubling of organic traffic in 10 months.
Our eCommerce SEO Strategy
Let’s face it; the SEO game has changed drastically. Gone are the days where all it took was a few lines of poorly written content and some backlinks to rank. Our fully-managed eCommerce SEO service consists of three different phases of work; Technical SEO Audit, Strategy Development, and Marketing. Each phase has its own set of deliverables and key performance indicators (KPI).
eCommerce SEO Audit
Before getting into the actual marketing part of SEO, we need to make sure that your website is ready for it. This means that we will conduct a full technical SEO audit of your eCommerce website to identify and fix most if not all of the on-page SEO issues that can be preventing your site from reaching the top of page 1 in search engines. Our Technical eCommerce Audits are designed to evaluate and fix the following:
- VISIBILITY ISSUES:
Page Errors, Redirects, Pages Blocked by Robots.txt, Malware - META ISSUES:
Missing or Duplicate Page Titles and Descriptions - CONTENT ISSUES:
Thin or Duplicate Content, Canonicalization, Topical Focus Issues
- LINK ISSUES:
Broken links, missing anchors and ALT texts, improper use of nofollow tags. - IMAGE ISSUES:
Broken images, missing title and ALT text. - SEMANTIC ISSUES:
Missing, duplicated headers, Schema.org microdata implementation.
eCommerce SEO Strategy Development
The eCommerce Marketing Research helps identify who your target audiences are and what they search for when looking for your products online.
By conducting this analysis we are able to better understand which queries are most likely being performed by searchers who are further down in their decision-making process and are closer to making a purchase.
- TARGET AUDIENCES:
Research and analysis of target demographics - INTENT OF SEARCH:
Analysis of demographically targeted intent of search and decision-making process - KEYWORD RESEARCH:
Keyword planning, analysis and identifying best keywords to target per page
- CONTENT IDEATION:
Social listening and competitive analysis for content topics - CONVERSION RATES:
Historic data analysis, implementation of best practices, identify fears, uncertainties, and doubts to assist with conversions
eCommerce SEO Marketing
This part of our eCommerce optimization process is designed to increase your website’s overall authority which aids in achieving higher rankings for relevant keywords and thus driving targeted traffic to your website.
Once your website is fully optimized (on-page SEO) and is compliant with eCommerce SEO best practices, it is ready for marketing. On a monthly basis our team of eCommerce experts will work on the following deliverables with the ultimate goal of increasing rankings and driving referrals to your site:
- CONTENT DEVELOPMENT:
Category and brand level page content rewrites, product page content curation and development. As well as content for your blog, which includes in-depth articles, infographics, influencer interviews and educational (how-to) articles. - BRAND BUILDING:
Manual and targeted outreach to bloggers, writers, webmasters and journalists to generate powerful backlinks in the form of brand mentions and featured articles. - ESTABLISHING EXPERTISE:
Contributing content and answering questions on “How-To” websites like Instructables.
- CONTENT MARKETING:
Utilizing native and social advertising platforms to amplify winning content pieces from your blog (infographics, articles, interviews) to drive targeted traffic to your website. - ECOMMERCE CONVERSION RATE OPTIMIZATION:
Weekly monitoring and recommendations based on best practices, A/B testing, data collected from Google Analytics and other tools. - ECOMMERCE CONVERSION TRACKING:
Implementation, monitoring, and reporting. - ONGOING TECHNICAL ECOMMERCE AUDITS:
Checking for errors, broken links, duplicate content and all other on-page ranking factors. - GOOGLE SEARCH CONSOLE MONITORING:
Checking crawls, errors, impressions, CTRs, backlinks. - KEYWORD RANK MONITORING
24/7 online access to our reporting system.
We’ve Been Exposing eCommerce Brands to Online Consumers Since 2009.
Our years of experience as eCommerce SEO experts have allowed us to refine our process to the point where we are so confident in our ability to deliver measurable results, that we offer our eCommerce SEO service without contract or obligation! You have nothing to lose, request a free consultation today.